
Au cœur de notre application Atome8 réside une grande quantité de données. La visualisation de ces données et l'extraction de schémas présentant un intérêt est un besoin primordial pour un pilotage efficace de l'activité. Nous nous sommes donc lancés dans une exploration des solutions de data visualisation disponibles et répondant à nos critères techniques, notamment le fonctionnement dans une architecture micro-services avec de multiples sources de données :
- Compatibilité docker : L'outil doit pouvoir s'intégrer aisément dans notre environnement conteneurisé via Docker.
- Support SQL et NoSQL : La solution doit interagir avec nos différentes bases de données, qu'elles soient relationnelles (SQL) ou non relationnelles (NoSQL).
- Support multi-sources : La capacité de créer des visualisations connectant des données provenant de sources distinctes était importante pour pouvoir lier les identifiants uniques à leur label, par exemple dans le cas où l'identiant et le label ne sont pas dans la même table ou base de données.
- Intégration : L'outil doit pouvoir être intégré au sein de notre application Atome8, si possible via des méthodes modernes (via des composants JS et non une iframe).
- Contextualisation : Il doit être possible d'adapter et de personnaliser les diagrammes en fonction de l'utilisateur ou d'un contexte donné (cabinet, organisation, etc).
Nous avons exploré plusieurs solutions, chacune présentant ses propres forces et faiblesses. Voici donc un rapide aperçu des outils que nous avons comparés avec notre petit retour.
Superset
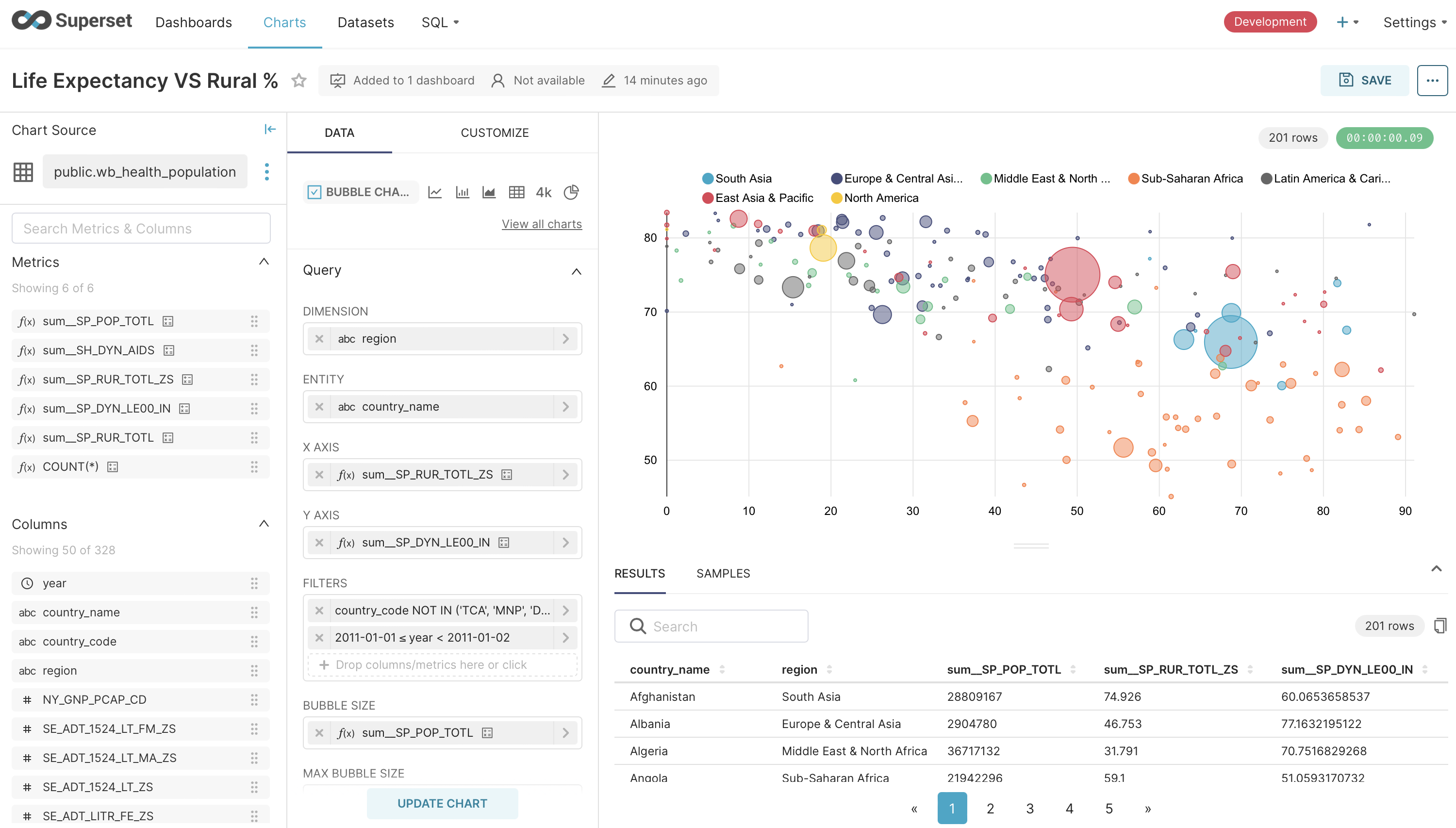
Superset est un outil robuste et complet pour l'exploration et la visualisation de données, particulièrement apprécié pour sa flexibilité et sa capacité à gérer de larges volumes de données. Son interface, bien que puissante, peut demander un temps d'adaptation.
- Excellente compatibilité avec docker et déploiement facile.
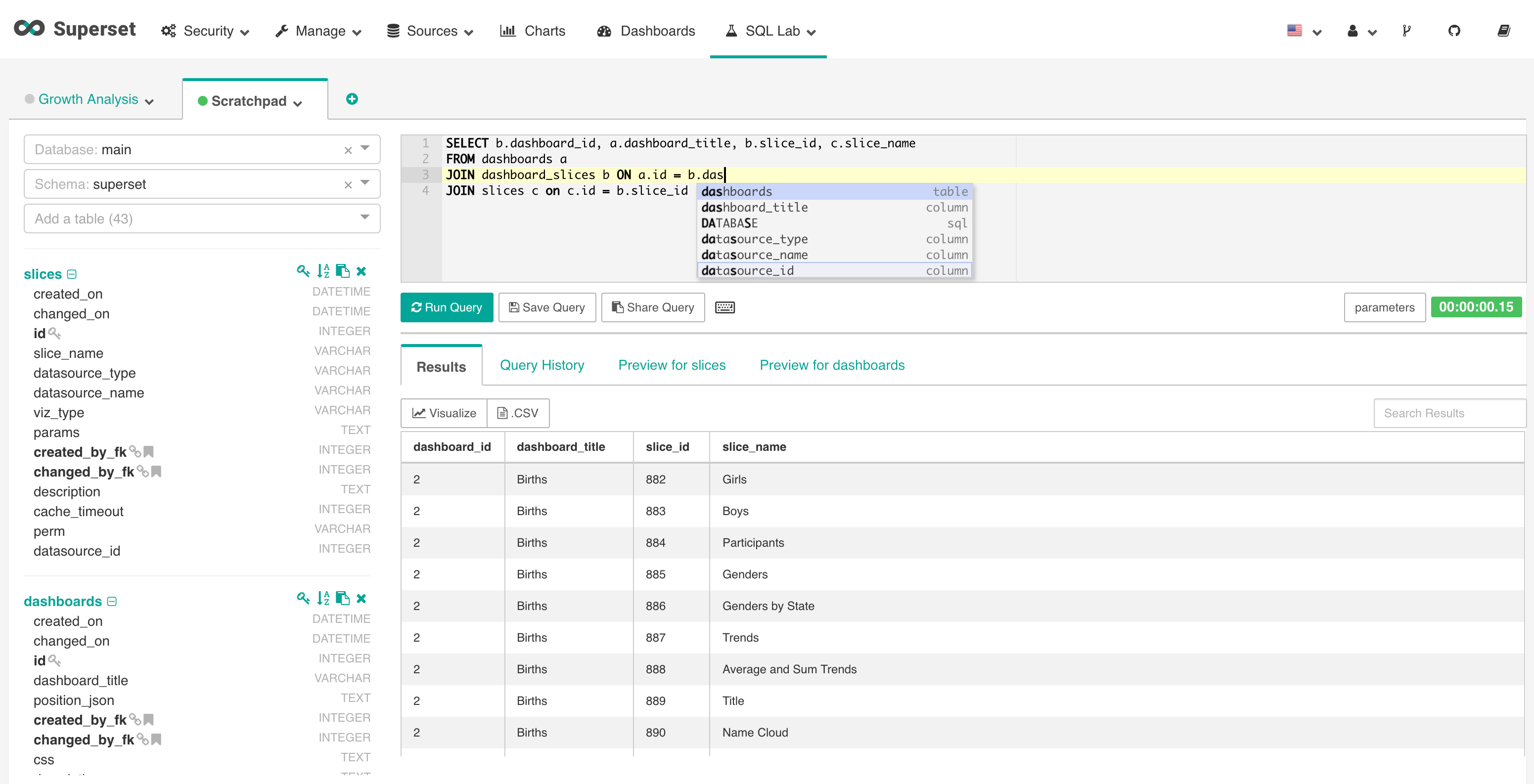
- Très bon support des bases de données SQL avec un explorateur ergonomique (SQL Lab).
- Offre un large choix de visualisations modernes et personnalisables.
- Le support natif pour les sources NoSQL est limité.
- L'intégration applicative se fait principalement via une iframe standard.
Redash
Redash est réputé pour sa simplicité d'utilisation, son interface épurée et sa facilité à rédiger des requêtes. Il est particulièrement apprécié des équipes qui souhaitent rapidement interroger leurs données et partager des tableaux de bord simples. Ses capacités de visualisation sont cependant plus basiques. C'est un logiciel Open Source avec une communauté de plus de 350 contributeurs.
- Très bonne compatibilité docker et déploiement facile.
- Support étendu d'une grande variété de sources de données, incluant SQL, NoSQL et même APIs.
- Interface utilisateur simple pour l'écriture de requêtes et la création de visualisations.
- Facilité de partage de tableaux de bord.
- Les capacités de visualisation sont plus limitées que celles de certains concurrents.
- La création de diagrammes nécessitant de joindre des données de sources différentes est difficile nativement et demande des contournements.
- L'intégration des tableaux de bord dans une application tierce, avec un filtrage sécurisé et granulaire et basé sur l'utilisateur de votre application peut être complexe selon la version et l'implémentation.
Lightdash
Lightdash se distingue par son approche moderne et sa forte intégration avec dbt, le rendant idéal pour les organisations qui ont déjà une architecture d'entrepôt de données bien établie. Il est souvent utilisé pour ses fonctionnalités d'intégration avancées dans des applications tierces et la sécurité au niveau des lignes.
- Très bonne compatibilité docker et facile à déployer.
- Forte intégration avec dbt pour une modélisation des données centralisée.
- Excellentes fonctionnalités d'intégration interactive et sécurisée.
- Très bon support de la contextualisation utilisateur via les "User Attributes" pour implémenter facilement du Row-Level Security (RLS).
- Présente une dépendance à l'écosystème dbt, impliquant souvent une architecture orientée entrepôt de données.
- Support natif limité pour les sources de données NoSQL directes.
- La capacité à créer des diagrammes multi-sources dépend de votre modèle de données dbt et de votre entrepôt de données, et non de Lightdash lui-même.
Grafana
Grafana est largement reconnu comme un outil extrêmement flexible et puissant, particulièrement dans les environnements de monitoring et d'observabilité. Sa vaste bibliothèque de plugins et sa capacité à se connecter à de nombreuses sources de données en font un choix polyvalent, bien que son constructeur de requêtes sans code puisse être moins intuitif pour certains.
- Excellente compatibilité docker et très utilisé dans les environnements conteneurisés.
- Support d'un très grand nombre de sources de données (SQL, NoSQL, time-series, etc.) grâce à son architecture de plugins.
- Capacités robustes pour créer des tableaux de bords multi-sources et utiliser des transformations pour combiner des données.
- Le constructeur de requêtes no code peut être moins intuitif que celui de Metabase, par exemple.
- La contextualisation est basée sur un système de variables.
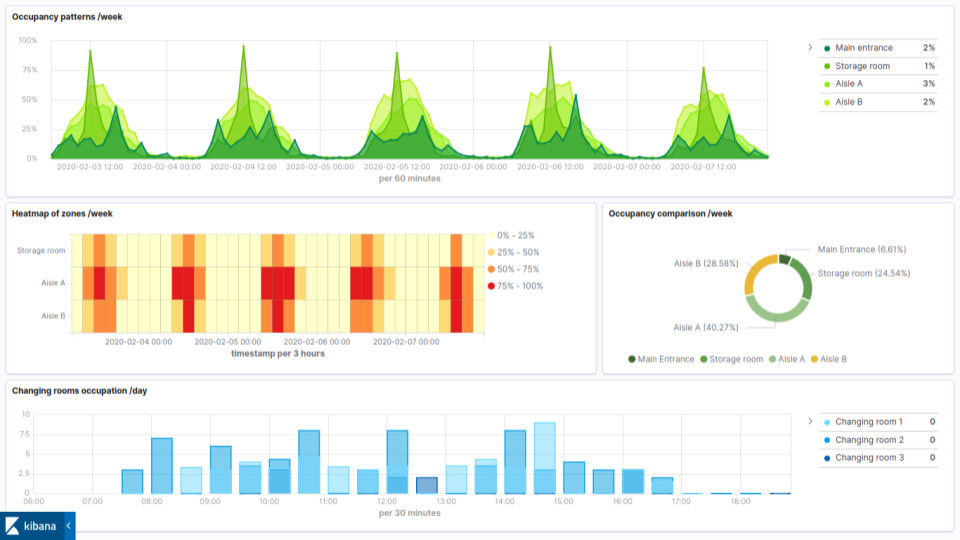
Kibana
Kibana est la solution de visualisation la plus adaptée aux données stockées dans ElasticSearch. Il excelle dans l'exploration de données de log et de séries temporelles, et est une pièce maîtresse de l'Elastic Stack. Cependant, sa forte liaison avec ElasticSearch limite son adaptabilité à d'autres types de bases de données.
- Très bonne compatibilité docker et facile à déployer.
- Excellent pour l'exploration et la visualisation de données stockées dans ElasticSearch (principalement NoSQL/document).
- Bonne gestion des utilisateurs et permissions au sein de l'écosystème Elastic Stack.
- Fortement lié à Elasticsearch ; le support d'autres bases de données externes (SQL ou NoSQL) est limité nativement.
- La création de diagrammes multi-sources est principalement limitée aux indices ElasticSearch. Il faut donc préalablement indexer les données à traiter.
- La contextualisation utilisateur fine dans les intégrations peut demander des efforts d'intégration spécifiques ou une structure d'indexation adaptée.
Metabase
Metabase est souvent cité pour son interface utilisateur intuitive et sa facilité d'adoption, même pour les utilisateurs non techniques. Il rend l'accès aux données simple et rapide, bien qu'il préconise une approche d'entrepôt de données pour les jointures complexes entre bases de données.
- Compatibilité docker et facile à déployer.
- Très facile à utiliser et ergonomique, y compris pour les utilisateurs non techniques.
- Supporte un bon nombre de bases SQL et certains NoSQL.
- Fonctionnalités d'intégration robustes et sécurisées, avec passage de paramètres.
- La jointure ou la liaison de données entre différentes bases de données n'est pas une fonctionnalité native et recommande l'utilisation d'un entrepôt de données en amont.
- Moins de flexibilité dans les options de visualisation avancées.
Notre choix
Pour notre usage, nous avons choisi Grafana car il permettait de répondre à nos différents besoins, sans devoir créer d'entrepôt de données ou d'indexer des données dans un moteur spécifique. Nous exposons ci-dessous comment Grafana permet de répondre à nos besoins en terme de visualisation.
Sources multiples
Afin de lier plusieurs bases de données dans un même diagramme, Grafana permet de définir la source d’une visualisation comme "mixteé puis de faire des requêtes à plusieurs sources. Il faut ensuite utiliser ensuite les transformations pour joindre les deux tables ou bases de données. Grafana supporte un grand nombre de type de source, ce qui était un de nos pré-requis.
Contextualisation
Le principe est de filtrer ou d'ajuster les données affichées dans un tableau de bord en fonction de la valeur d'une ou plusieurs variables. Ces variables peuvent être alimentées de différentes manières :
- Identifiant de session/utilisateur : Lorsque l'utilisateur se connecte, son identifiant unique est capturé et utilisé pour filtrer les données qui lui sont spécifiquement associées. Par exemple, un dirigeant ne verra que les données de son entreprise, et non celles de tous les cabinets.
- Profil de l'utilisateur : Des attributs stockés dans le profil de l'utilisateur (rôle, département, cabinet d'expertise comptable) peuvent servir de variables. Si un utilisateur est lié à un cabinet d'experts, la variable "cabinet d'expert" prendra la valeur de ce cabinet.
- Paramètres d'URL : Les variables peuvent être passées directement via l'URL. C'est utile pour partager des vues spécifiques ou pour intégrer des liens depuis d'autres applications.
- Sélection manuelle : L'utilisateur peut parfois choisir la valeur d'une variable via un menu déroulant ou un filtre sur le tableau de bord lui-même. C'est pratique pour permettre à un administrateur de basculer entre différentes vues.
Ces variables sont ensuite utilisées dans les requêtes de base de données ou les filtres des outils de visualisation pour récupérer ou afficher uniquement les données qui correspondent aux critères définis par la variable. Avec cette approche, il est possible de mettre en place des tableaux de bord spécifiques par utilisateur.
Intégration
Intégration via iframe
Grafana permet d'intégrer facilement des tableaux de bord ou des panneaux spécifiques dans une application web via des iframes. Chaque tableau de bord ou panel peut être accédé via une URL spécifique, à laquelle on peut ajouter des paramètres de visualisation (comme la période de temps ou les variables utilisées). Cette approche permet d’afficher dynamiquement les données directement dans l’interface utilisateur de l’application, sans rediriger l'utilisateur vers Grafana. Il est également possible de masquer l’interface de Grafana (menus, barres de navigation, etc.) pour une intégration plus fluide, à l’aide du paramètre &kiosk=tv ou &fullscreen=true.
Authentification et sécurité
Grafana prend en charge plusieurs mécanismes d’authentification qui facilitent l’intégration sécurisée avec des applications existantes :
- SSO (Single Sign-On) via OAuth2, LDAP, SAML, ou des en-têtes HTTP, pour permettre une authentification automatique de l'utilisateur depuis l’application.
- Tokens d’accès (API keys) pour les intégrations machine à machine ou les accès restreints.
- Possibilité de restreindre les droits d’accès à certains tableaux de bord ou dossiers en fonction du rôle de l’utilisateur, ce qui permet une gestion fine de la visibilité au sein d’une organisation.
Accès et modification par API
Grafana expose une API REST complète permettant de :
- Créer ou modifier dynamiquement des tableaux de bord.
- Gérer les utilisateurs et les droits d’accès.
- Mettre à jour des variables ou des annotations.
- Automatiser l'import/export de tableaux de bord entre environnements (ex : développement, préproduction, production).
Grâce à cette souplesse, nous pouvons intégrer Grafana de manière fluide dans notre application métier, tout en conservant une sécurité et une personnalisation adaptées aux profils utilisateurs.
Pour conclure, il existe un large panel d’outils de visualisation des données, présentant chacun des points forts et des points faibles. Il est donc important d’étudier vos propres contraintes, puis d'envisager les différentes solutions et si possible de les essayer, afin de faire un choix éclairé. Si vous recherchez une société pour vous accompagner dans la mise en place d'outils de visualisation de données, n'hésitez pas à nous contacter.