
Nous sommes partis de cette question : comment faciliter et faire gagner du temps aux utilisateurs dans le traitement de leurs documents de la GED comptable de notre plateforme Atome8 ? Le plus chronophage est de déterminer le type de document, car il faut alors parcourir le document en question puis trouver le type adéquat. Implémenter une solution de classification automatique des documents via un outil d'apprentissage machine (ML) et d'IA semblait tout indiqué.
Avant de commencer, nous avions exploré les solutions et les modèles existants. Cette phase de recherche nous a permis de comprendre les différentes approches possibles et d'identifier les outils les plus pertinents pour notre contexte.
Décomposition du projet
Notre projet se décompose en trois étapes clés :
- Extraction du contenu des documents : Cette étape consiste à extraire les informations pertinentes des documents, qu'il s'agisse de texte contenu dans des fichiers PDF, ou d'images contenant du texte.
- Classification des documents par catégories : Une fois le contenu extrait, il s'agit de l'analyser et de déterminer quelles sont la ou les catégories les plus probables. Pour obtenir des performances optimales, il faut utiliser un set de données d'entraînement spécifique aux données traitées.
- Utilisation en tant qu'API : Enfin, il doit être possible d'utiliser ces fonctionnalités de classification via une API pour l'intégrer dans le logiciel existant.

Solutions technologiques
Deux approches principales ont été étudiées :
- Solutions Cloud : Ces solutions proposent des API et des services pré-entraînés, souvent basés sur des modèles d'apprentissage profond. Elles offrent une intégration rapide et une scalabilité aisée, par exemple, via AWS Bedrock.
- Développement d'une solution sur mesure : Cette option consiste à développer une solution sur mesure, en utilisant des librairies et des modèles d'apprentissage automatique pré entraînés. Elle offre plus de contrôle et de personnalisation, mais demande plus de ressources en développement.
Notre choix et son implémentation
Pour implémenter une classification intelligente de nos documents au sein de la GED, nous avons exploré ces deux options. Les solutions cloud offraient l'avantage d'une mise en œuvre rapide grâce à des API pré-entraînées sur d'immenses corpus de données. Cependant, nos besoins spécifiques en termes de catégories et de vocabulaire métier (comptabilité) nous ont conduits à opter pour le développement d'une solution interne en Python avec FastAPI. Ce choix nous offre une plus grande flexibilité et un contrôle total sur le processus de classification.
Les étapes de notre implémentation
Notre approche s'est composé de plusieurs étapes que nous avons menées itérativement.
Création du set de données (dataset)
La première étape cruciale a été la constitution d'un dataset de qualité. Nous avons rassemblé un ensemble conséquent de documents comptables provenant de la GED actuelle de la plateforme Atome 8. Ce set de données a été nettoyé et étiqueté afin de servir de base d'apprentissage pour notre modèle. Un dataset propre et représentatif est essentiel pour la performance du modèle : plus le dataset est important et varié, plus le modèle sera performant. De plus, il faut que le nombre de documents par catégories soit similaire pour ne pas avoir de prédictions éloignées de la réalité sur certaines catégories.
Le fichier CSV final est composé d'une ligne par document avec deux colonnes : "Texte" pour le contenu extrait du document PDF ou de l'image, "Label" pour la catégorie (étiquette) du document.
Affinage du modèle (fine tuning)
Hugging Face est une plateforme collaborative en ligne permettant de créer et partager des modèles et des logiciels de machine learning. De nombreux composants open source en python pour le machine learning sont également proposés par cette société, et ce sont certains de ces composants que nous allons utiliser par la suite : Dataset, Transformers, Tokenizer, etc.
Plus concrètement, nous avons utilisé la librairie transformers de Hugging Face pour charger le modèle pré-entraîné distill-BERT, et l'affiner sur notre set de données comptables.
Voici les étapes de notre programme :
Préparation des données
- Chargement et conversion du type des données : Le fichier CSV est chargé dans un DataFrame pandas, une librairie python facilitant la manipulation des données. Les colonnes "Texte" sont converties en chaînes de caractères pour éviter les erreurs potentielles liées aux types de données.
- Gestion des valeurs manquantes : Les lignes contenant des valeurs manquantes dans les colonnes "Texte" ou "Label" sont supprimées pour garantir la qualité des données d'entraînement.
- Encodage des labels : Les labels textuels sont convertis en valeurs numériques à l'aide d'un LabelEncoder de scikit-learn (plus simple à utiliser que celui de pytorch). Cet encodage est essentiel pour l'entraînement du modèle. La correspondance entre les labels originaux et les labels encodés est sauvegardé pour une utilisation ultérieure lors de l'inférence.
- Création du Dataset Hugging Face : Le DataFrame pandas est transformé en un objet Dataset de la librairie datasets de Hugging Face. Ce format est optimisé pour l'entraînement avec des modèles Transformers.
- Mélange et division des données : Le dataset est mélangé aléatoirement pour assurer une distribution équilibrée des exemples dans les ensembles d'entraînement et de test. Il est ensuite divisé en deux ensembles : 80% pour l'entraînement et 20% pour l'évaluation.
- Tokenisation : On utilise le tokenizer DistilBertTokenizerFast pour convertir le texte en entrées numériques compréhensibles par le modèle. Le texte est tronqué à une longueur maximale de 128 tokens et complété (via du padding) si nécessaire. Cette étape est appliquée aux deux ensembles, entraînement et test.
Fine-tuning du modèle
- Chargement du modèle pré-entraîné : Le modèle AutoModelForSequenceClassification de Hugging Face est chargé avec le modèle pré-entraîné distilbert-base-uncased. Le nombre de labels (classes) est spécifié lors du chargement.
- Définition des métriques d'évaluation : Il s'agit de calculer les métriques d'évaluation suivantes : "accuracy", "F1-score" pondéré, précision pondérée et rappel pondéré. Ces métriques permettent d'évaluer les performances du modèle pendant l'entraînement.
- Configuration de l'entraînement : Un objet configure les paramètres de l'entraînement.
- Création du Trainer : L'objet Trainer de Hugging Face gère l'entraînement du modèle. Il prend en entrée le modèle, les arguments d'entraînement, les datasets d'entraînement et d'évaluation, et la fonction de calcul des métriques.
- Entraînement : La méthode "trainer.train()" lance le processus de fine-tuning. Le modèle est entraîné sur l'ensemble d'entraînement et évalué sur l'ensemble de test à chaque époque.
- Sauvegarde du modèle, du tokenizer et du label encoder : Après l'entraînement, le modèle affiné, le tokenizer et le label encoder sont sauvegardés. Le modèle en lui-même est un répertoire contenant plusieurs fichiers, qui sont automatiquement chargés lorsqu'on utiliser le modèle pour réaliser des prédictions. Le LabelEncoder est également sauvegardé pour pouvoir décoder les prédictions du modèle en labels textuels lors de l'utilisation de l'API.
Hyper-paramètres
Le fine-tuning d'un modèle de classification nécessite d'ajuster plusieurs paramètres, appelés hyper-paramètres, qui ont un impact direct sur la performance du modèle. Ces hyper-paramètres permettent de contrôler différents aspects de l'entraînement, tels que :
- Le stockage des résultats: Un paramètre permet de spécifier le répertoire où seront enregistrés les résultats de l'entraînement, incluant les différentes versions du modèle et les mesures de performance.
- Le nombre d'époques d'entraînement: Un paramètre contrôle le nombre de fois que le modèle parcourt l'ensemble des données d'entraînement. Un nombre trop élevé peut entraîner un sur-apprentissage, tandis qu'un nombre trop bas peut empêcher le modèle d'apprendre correctement.
- La taille des lots d'entraînement et d'évaluation: Ces paramètres définissent le nombre d'échantillons de données utilisés pour l'entraînement et l'évaluation à chaque étape. Ils influencent la vitesse de l'entraînement et l'utilisation de la mémoire.
- Le taux d'apprentissage: Ce paramètre détermine la vitesse à laquelle le modèle ajuste ses poids en fonction des erreurs qu'il commet. Un taux trop élevé peut nuire à la convergence, tandis qu'un taux trop bas peut ralentir l'apprentissage.
- L'échauffement du taux d'apprentissage: Un paramètre permet de commencer l'entraînement avec un taux d'apprentissage faible et de l'augmenter progressivement. Cela aide le modèle à mieux converger au début de l'entraînement.
- La régularisation: Un paramètre permet d'appliquer une régularisation pour éviter le sur-apprentissage. La régularisation consiste à pénaliser les poids trop importants pour empêcher le modèle de se spécialiser sur les données d'entraînement.
- La stratégie d'évaluation: Un paramètre détermine à quelle fréquence le modèle est évalué sur les données de validation.
- La fréquence d'affichage des logs: Ce paramètre contrôle la fréquence à laquelle les informations sur l'entraînement sont affichées.
- L'accumulation des gradients: Un paramètre permet de simuler une taille de lot plus grande en accumulant les gradients sur plusieurs étapes. Cela peut être utile lorsque la mémoire GPU est limitée.
- L'entraînement en précision réduite: Un paramètre permet d'activer l'entraînement en précision flottante 16 bits pour réduire la consommation de mémoire et accélérer les calculs.
- Le type de "scheduler" du taux d'apprentissage: Ce paramètre permet de choisir une méthode pour ajuster le taux d'apprentissage au cours du temps. Par exemple, un "scheduler" cosinusoïdal réduit progressivement le taux d'apprentissage, ce qui favorise une convergence plus stable à la fin de l'entraînement.
En résumé, le choix et l'ajustement de ces hyper-paramètres sont essentiels pour optimiser les performances du modèle, en termes de précision et de vitesse d'entraînement, tout en évitant le sur-apprentissage et en tenant compte des ressources disponibles.
Évaluation et rapport
Après l'entraînement, le modèle est évalué sur l'ensemble de test. Les prédictions sont obtenues à partir du modèle et comparées aux labels réels. Un rapport de classification est généré à l'aide de la fonction classification_report de scikit-learn (plus simple à utiliser que celle de pytorch), fournissant des informations détaillées sur les performances du modèle pour chaque classe.
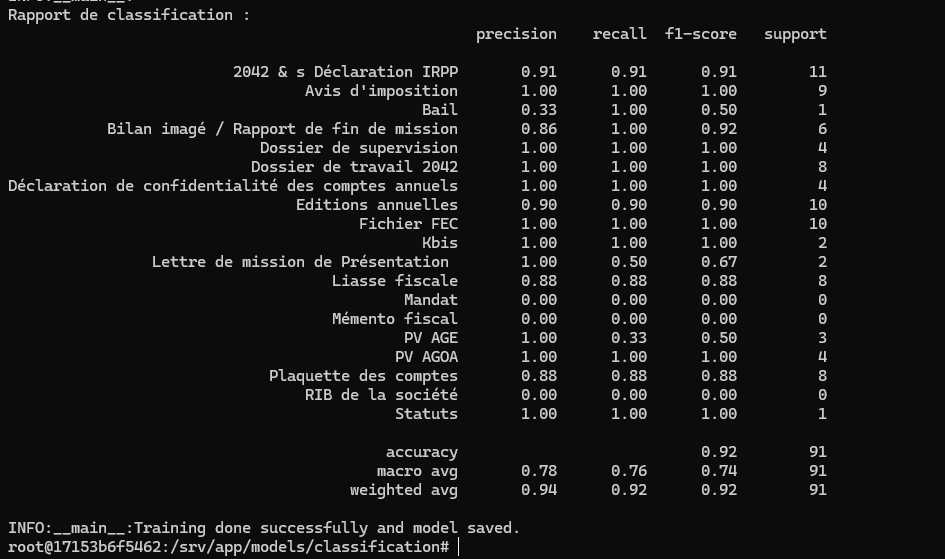
Voici quelques explications sur les métriques affichées :
- Precision : Cela permet de mesurer la précision des prédictions positives. Une précision élevée signifie que le modèle est capable d'éviter les faux positifs pour cette catégorie. Il ne commet pas beaucoup d'erreurs lorsqu'il prédit cette catégorie.
- Recall : Cela mesure la capacité du modèle à trouver tous les documents de cette catégorie. Un recall élevé signifie que le modèle est capable d'éviter les faux négatifs pour cette classe. Il capture la plupart des documents qui sont réellement de cette catégorie.
- Score F1 : C'est une note unique qui équilibre à la fois la précision et le rappel. Un score F1 élevé indique à la fois une précision et un rappel élevés. Il s'agit d'une bonne mesure globale des performances d'un modèle pour une classe spécifique.
- Support : C'est le nombre d'instances réelles de chaque catégorie dans l'ensemble de test. Il s'agit simplement du nombre de fois où chaque catégorie apparaît réellement. Le support vous indique combien de documents vous avez pour chaque catégorie. Il est important pour comprendre le contexte des autres mesures. Par exemple, une précision élevée pour une catégorie dont le support est très faible peut ne pas être très significative.
- Accuracy : C'est la proportion globale de prédictions correctes (positives et négatives) sur l'ensemble des prédictions. L'accuracy est une mesure simple et intuitive, mais elle peut être trompeuse si les catégories sont déséquilibrées, il vaut donc mieux se fier à cette métrique uniquement avec des catégories équilibrées.
- Macro average : C'est la moyenne non pondérée des mesures par catégorie (précision, rappel ou score F1). Elle traite toutes les catégories de la même manière, quel que soit leur support. C'est utile lorsque vous souhaitez évaluer les performances du modèle dans toutes les catégories sans être influencé par le déséquilibre de ces catégories.
- Weighted average : La moyenne pondérée des mesures par classe, où la contribution de chaque catégorie est pondérée par son support.
Dans cet exemple, il est clair que le support de nombreuses catégories est insuffisant pour avoir des performances correctes. Le dataset utilisé doit être complété et amélioré, en ajoutant des échantillons pour les catégories dont le support est nul ou inférieur à un seuil donné.
Le traitement des données
Nous avons créé un script Python pour extraire et nettoyer le texte des documents de la GED.
Récupération du document : À partir de l'identifiant (UUID) d'un document, une fonction récupère l'URL du fichier physique sur le serveur distant. Dans notre architecture micro-services de la plateforme Atome8 nous utilisons un serveur AWS S3.
Téléchargement du document : Une fonction gère le téléchargement du document à partir de son URL. Elle gère différents types de fichiers (PDF, images, textes, etc.) et s'assure que le fichier est téléchargé correctement. Elle gère également les erreurs potentielles lors du téléchargement.
Extraction du texte : Cette fonction est le cœur de l'extraction de texte. Elle prend en entrée le chemin du fichier téléchargé et détermine le type de fichier. Ensuite, elle appelle la fonction d'extraction appropriée selon le type
- Gestion des PDF : Pour les fichiers PDF, une gestion spécifique est mise en place : si l'extraction directe du texte échoue (s'il est scanné, par exemple) alors une conversion en images est tentée, suivie d'une reconnaissance optique de caractères (OCR). Cette fonction gère également le prétraitement de l'image avant l’exécution de l'OCR et le nettoyage des fichiers temporaires.
Prétraitement du texte : On effectue un nettoyage du texte, incluant la suppression des caractères de nouvelle ligne, des espaces multiples et de certains caractères spéciaux. Cette étape est cruciale pour garantir la cohérence des données.
Retour du résultat : Le texte extrait et pré-traité est prêt pour l'étape suivante.
Prédiction du type de document
Nous utilisons maintenant le modèle pré-entraîné que nous avons affiné avec notre propre set de données, ainsi que le tokenizer et le label encoder dont nous parlions plus haut :
- Classification du texte : La fonction de prédiction prend en entrée le texte pré-traité, le tokenizer, le modèle de classification et le chemin vers l'encodeur de labels. Elle effectue les étapes suivantes :
- Charge l'encodeur de labels.
- Tokenise le texte.
- Effectue une prédiction avec le modèle.
- Calcule les probabilités pour chaque classe à l'aide de la fonction "softmax".
- Retourne les 3 meilleures prédictions avec leurs probabilités (scores de confiance).
- Stockage vectoriel : Nous utilisons une base de données vectorielle Qdrant dans le cadre de ce projet. Une fonction interagit avec la base de donnée Qdrant, elle prend en entrée l'identifiant du document, son type, le texte extrait et le nom de la collection. Elle effectue les actions suivantes :
- Vérifie si la collection existe et la crée si nécessaire.
- Charge le modèle SentenceTransformer pour générer le vecteur (embedding) du texte.
- Crée un point (vecteur et métadonnées) dans la base de données vectorielle. L'identifiant du document sert d'identifiant unique pour le point. Les métadonnées incluent le type de document et la prédiction.
Cette base de données n'est pas utilisée dans le cadre de la classification, mais elle nous permettra par la suite de mettre en place de nouvelles fonctionnalités d'IA telle que de la recherche par prompt dans notre base de document.
- Création des endpoints d'API : Un endpoint d'API est créé à l'aide de FastAPI, il prend en entrée l'identifiant du document. Cet endpoint effectue les opérations suivantes :
- Récupère l'URL du document à partir de l'identifiant.
- Télécharge le document.
- Extrait et pré-traite le texte du document.
- Classifie le texte à l'aide de la fonction dédiée.
- Enregistre le document et sa prédiction dans la base de données vectorielle.
- Retourne les 3 prédictions.
Une protection est ajoutée pour restreindre l'accès à l'API aux adresses IP autorisées. Les erreurs potentielles sont gérées et des réponses HTTP appropriées sont renvoyées. Notre API de classification automatique est prête ! Il ne reste plus qu'à adapter la plateforme Atome8 pour y intégrer cette nouvelle fonctionnalité.
En savoir plus
Le développement d'une API Python avec des modèles pré-entraînés affinés nous a permis de répondre précisément à nos besoins. Cette approche offre une grande flexibilité, une adaptation fine à notre vocabulaire métier et une maîtrise complète du processus. Les prochaines étapes de notre équipe R&D incluent l'ajout de fonctionnalités intelligentes pour notre GED telles qu'un prompt sous forme de ChatBot pour retrouver rapidement des informations sur les documents stockés.
Contactez-nous si vous souhaitez mettre en place des solutions d'automatisation et d'IA pour gagner du temps dans votre organisation.